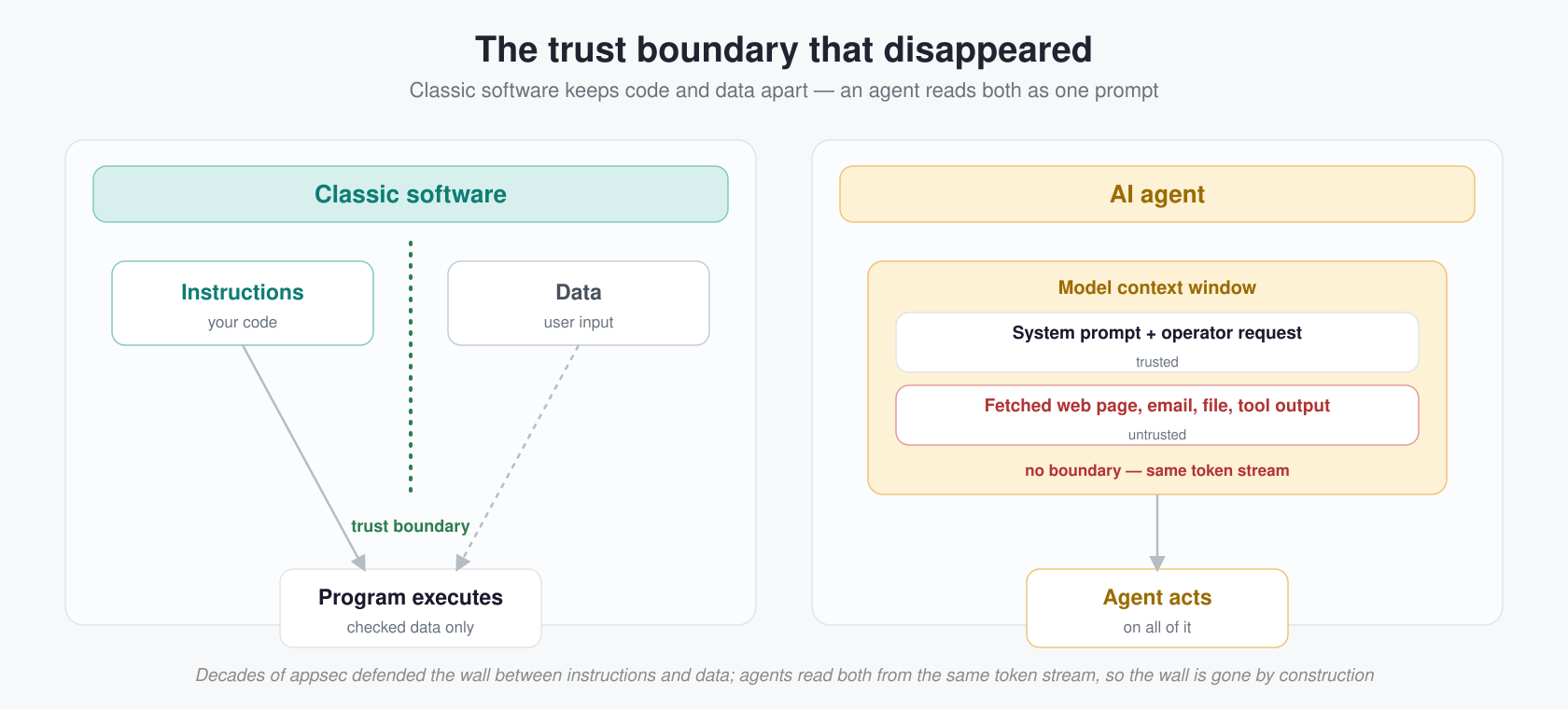
An AI-powered geospatial intelligence application that autonomously analyzes satellite imagery, vessel traffic, and road congestion to answer natural language questions about any area on Earth.
Draw an area on a map, ask a question, and the agent picks the right data sources : satellite catalogs for land and vegetation, Global Fishing Watch for maritime traffic, TomTom for road congestion then streams results back in real time.
The agent plans and executes multi-step analysis workflows — searching satellite catalogs, downloading spectral bands, computing vegetation or water indices, querying vessel tracking databases, sampling road traffic conditions, running visual interpretation with Claude Vision, and streaming every result back in real time.
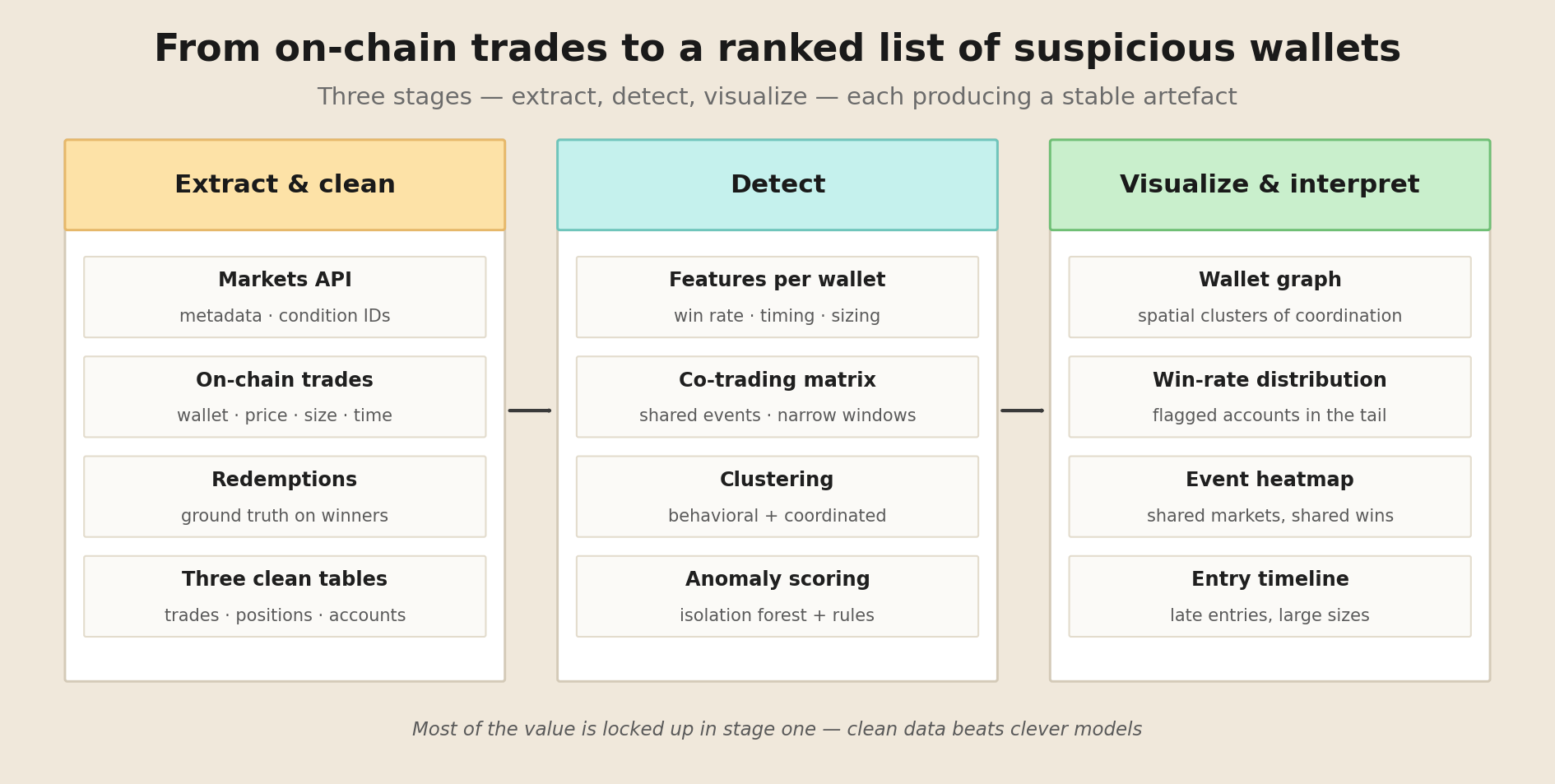
The system is organized into five layers, each with a clear responsibility:

Frontend — A React 18 + TypeScript SPA served by Vite. Mapbox GL JS renders a satellite basemap where users draw AOI polygons via Mapbox Draw. A chat panel displays streaming Markdown responses, tool-status cards, and inline imagery previews. Zustand manages client state; a single WebSocket connection per conversation carries all real-time traffic.
API Layer — FastAPI exposes a REST surface for conversation CRUD (/api/conversations) and cached imagery serving (/api/imagery). The main entry point is a WebSocket endpoint (/ws/chat/{conversation_id}) that accepts user messages, persists them in PostgreSQL, launches the agent, and relays streamed events (tokens, tool starts/ends, imagery references) back to the client.
Agentic Core — A LangGraph StateGraph that implements a ReAct-style loop with automatic data source routing. On each turn the graph: (1) injects a system prompt with the current AOI bounding box and date context, (2) calls the LLM (Anthropic Claude Sonnet), (3) checks whether the LLM produced tool calls — if yes, routes to a ToolNode that executes them and feeds results back to the LLM; if no, the turn ends. The agent decides which intelligence type to use (satellite imagery, vessel traffic, or road traffic) based on the user's question.
Services — Four domain services sit behind the tools:
stac.py— wrapspystac-clientto search and sign Sentinel-2 L2A items from Microsoft Planetary Computer.raster.py— handles COG downloads (parallel, bbox-clipped viarasterio), spectral index computation (NDVI, NDWI, NBR with NumPy), RGB composite generation, and PNG export with.bounds.jsonsidecar files for geo-referenced map overlays.vessel.py— queries the Global Fishing Watch API for vessel detections (SAR + AIS), with type aggregation and temporal comparison.traffic.py— queries the TomTom Traffic API for road congestion data, sampling a grid of points across the AOI.
External Services — Microsoft Planetary Computer (Sentinel-2 L2A STAC catalog and COG storage), Global Fishing Watch (vessel detection API), TomTom (traffic flow API), PostgreSQL 16 (conversations and messages), and the Anthropic API (LLM reasoning + Vision analysis).
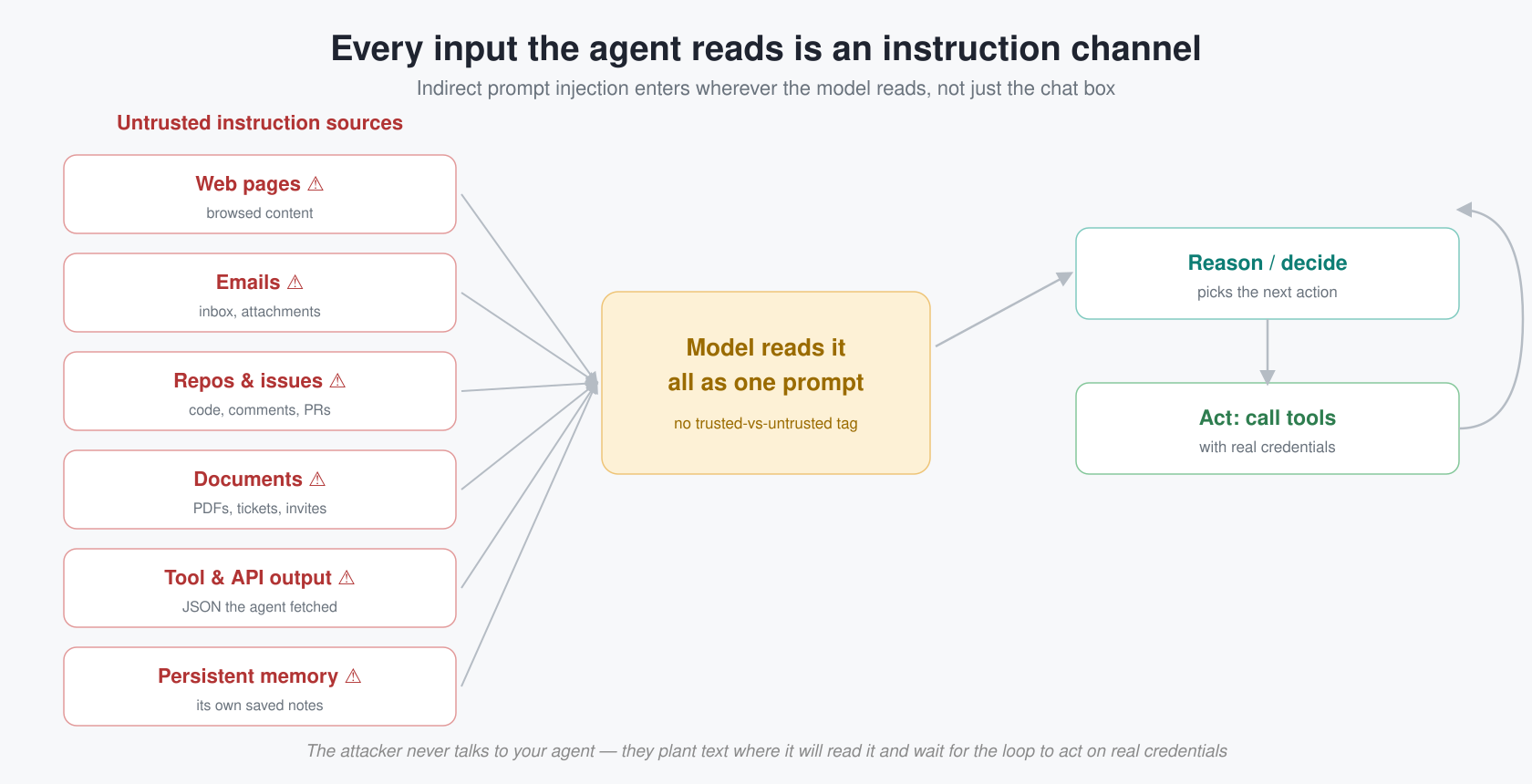
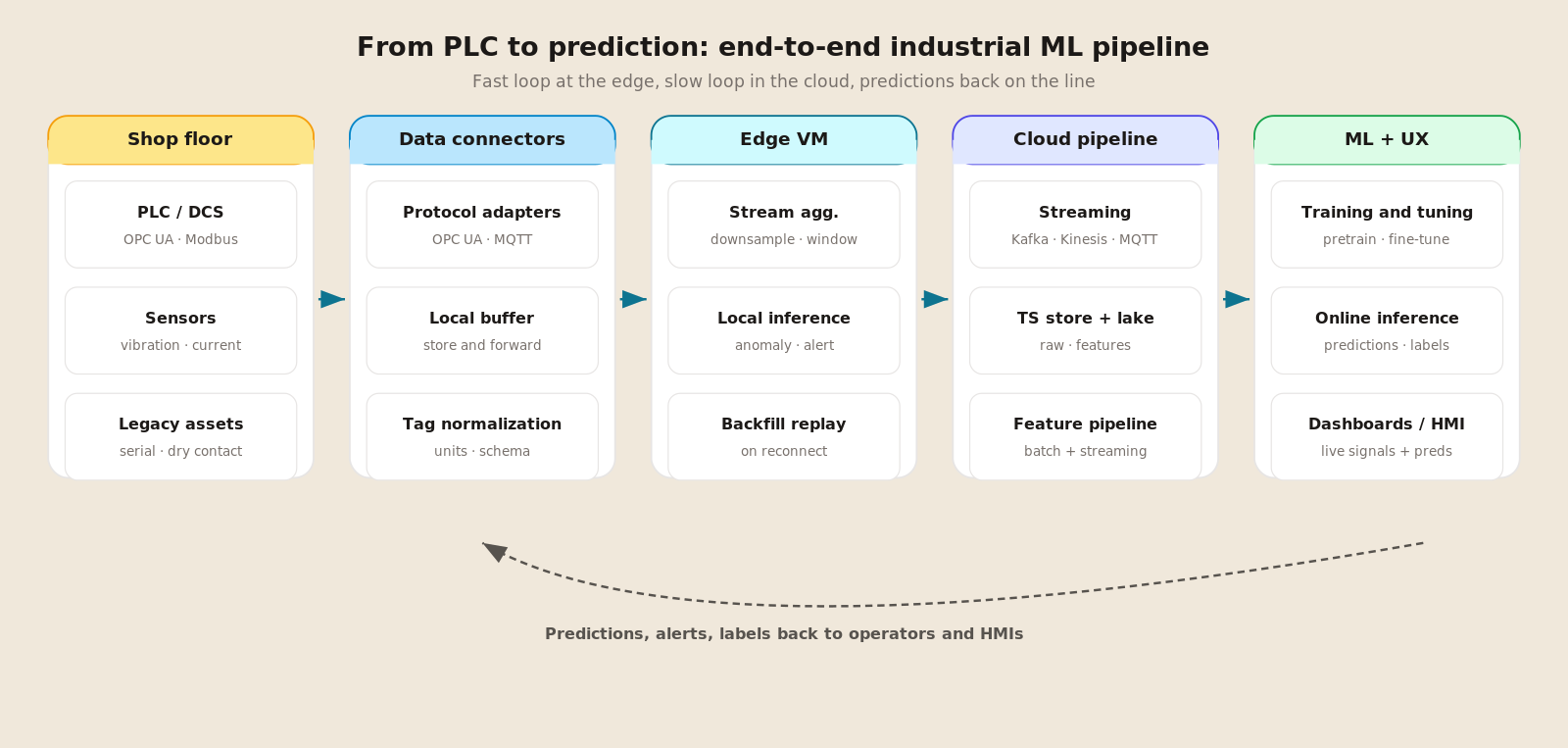
The agent follows a plan-then-execute pattern driven entirely by the LLM. There is no hard-coded pipeline — Claude decides which tools to call and in what order based on the user's question and the AOI context. A typical multi-step session looks like:
- Search —
search_imageryqueries the Planetary Computer STAC API with the AOI bbox, a date range (the LLM resolves relative dates like "last month"), and a cloud-cover threshold. Returns a ranked list of scenes. - Download —
download_imageryordownload_imagery_batchfetches specific spectral bands (e.g. B04, B08 for NDVI) as COG tiles, clipped to the AOI. Batch mode parallelizes across scenes for temporal comparisons. - Compute —
compute_indexderives a spectral index (NDVI, NDWI, or NBR) from downloaded bands, produces a colorized PNG with statistics (min, max, mean). - Analyze —
analyze_imagesends a PNG to Claude Vision for qualitative interpretation (land-cover description, anomaly detection). - Compare —
compare_imagescomputes a pixel-level difference map between two dates, highlighting areas of change.
The LLM may skip steps, reorder them, or loop (e.g., searching again with relaxed cloud cover if the first search returned too few results). Every tool invocation streams status updates to the frontend so the user sees progress in real time.
| Tool | Description |
|---|---|
search_imagery |
Search STAC catalogs by bounding box, date range, cloud cover. Recommends the 2 best scenes (lowest cloud, best temporal spread). |
download_imagery |
Download specific spectral bands from a single Sentinel-2 scene |
download_imagery_batch |
Download the same bands for up to 2 scenes in parallel |
compute_index |
Compute NDVI, NDWI, or NBR and produce colorized PNG + stats |
analyze_image |
Visual analysis of imagery using Claude Vision |
compare_images |
Pixel-level difference map between 2 dates with change highlighting |
| Tool | Description |
|---|---|
search_vessels |
Search for vessel detections in an AOI between two dates (Global Fishing Watch, SAR + AIS, vessels >25m) |
compare_vessel_traffic |
Compare vessel counts and type breakdowns between two time periods, with delta |
| Tool | Description |
|---|---|
search_traffic |
Get current road congestion in an AOI (TomTom — average speed, free-flow speed, congestion level) |
compare_traffic |
Compare current traffic conditions against free-flow baseline |
| Layer | Technologies |
|---|---|
| Frontend | React 18, TypeScript, Vite, Tailwind CSS, Mapbox GL JS, react-map-gl, Zustand |
| Backend | Python, FastAPI, SQLAlchemy (async), asyncpg, Uvicorn |
| Agent | LangGraph, LangChain Anthropic, LangChain Core |
| Geospatial | pystac-client, planetary-computer, rasterio, NumPy, Shapely, Pillow |
| Data APIs | httpx (Global Fishing Watch, TomTom Traffic) |
| Infra | Docker Compose, PostgreSQL 16, Alembic |
- Docker and Docker Compose
- Anthropic API key
- Mapbox access token (free tier)
- Global Fishing Watch API key (free) — for vessel traffic
- TomTom API key (free tier — 2,500 calls/day) — for road traffic
-
Clone and configure:
cp .env.example .env # Edit .env and set your API keys: # ANTHROPIC_API_KEY, MAPBOX_TOKEN, VITE_MAPBOX_TOKEN # GFW_API_KEY (vessel traffic), TOMTOM_API_KEY (road traffic)
-
Start all services:
docker-compose up --build
-
Open the app: http://localhost:5173
cd backend
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
uvicorn app.main:app --reload --port 8000Requires a PostgreSQL instance at the DATABASE_URL in .env.
cd frontend
npm install
npm run dev- Draw a polygon or rectangle on the map to define your Area of Interest
- Ask a question in the chat — for example:
- "Find recent cloud-free imagery of this area"
- "Show me the vegetation health (NDVI) for this region"
- "Compare land cover between January and March 2025"
- "What can you see in the latest satellite image of this area?"
- "How has vessel traffic changed in this port between January and March?"
- "What's the current road congestion in this area?"
- The agent autonomously picks the right data sources, plans the analysis, and streams results back in real time
- Click Show on map on any imagery result to overlay it on the map
- 2-scene comparison — Temporal comparisons always use exactly 2 dates. The agent picks the best pair (lowest cloud cover, maximum temporal spread).
- Area limits — AOIs above ~200 km² trigger automatic downsampling for performance. AOIs above ~2,000 km² are rejected.
- Vessel detection — Global Fishing Watch detects vessels >25m using satellite SAR + AIS. Smaller vessels may not appear.
- Road traffic — TomTom provides congestion levels (speed vs free-flow), not absolute vehicle counts. If you need exact counts, government traffic sensors are the only free source (fixed locations only).